

丁勇教授团队两篇最新成果入选计算机视觉国际顶级会议ECCV 2022




独家抢先看
近日,计算机视觉国际顶级会议European Conference on Computer Vision(ECCV)2022公布了论文的收录结果,浙江大学微纳电子学院丁勇教授课题组自动驾驶研究团队共有2篇成果入选,其中1篇接收为口头报告(Oral Presentation)论文。
1.背景介绍
1.1 ECCV
European Conference on Computer Vision(ECCV)与International Conference on Computer Vision and Pattern Recognition(CVPR)、International Conference on Computer Vision(ICCV)并称计算机视觉三大顶级会议。ECCV每两年举行一次,与ICCV交替举行。据2022年最新公布的Google Scholar Metrics,ECCV在Computer Vision and Pattern Recognition大类的全球出版物中排行第3,在Engineering & Computer Science大类的全球出版物中排行第15。据主办方统计,本届ECCV 2022论文总投稿数超过8170篇,其中1629篇论文中选,录用率不到20%,而Oral Presentation入选率仅为2.7%,代表着行业领先水平。
1.2团队介绍
丁勇教授带领的自动驾驶研究团队始建于2018年,发轫于与上海云骥智行智能科技有限公司的联合创始人兼SVP罗春博士的合作,罗春博士曾率领公司成功收购瑞典沃尔沃汽车自动驾驶技术,在国内实现自动驾驶产品量产(国内第一家)。经过多年的潜心积累,研究团队先后与俄罗斯国立莫斯科大学、MBZUAI大学、上海云骥智行智能科技有限公司等建立密切的产教融合深度合作,联合承担了国家重点研发计划国际科技合作等重大科研项目,联合发表学术论文20余篇。研究团队在自动驾驶技术的前端感知到决策规划等多个关键环节具有较强的研究储备和算法创新,所研算法的性能均达到国际领先和先进水平。目前,在图像3D目标检测任务上发表国际顶级会议CVPR论文2篇、ECCV论文1篇,获CVPR 2022 Waymo 纯视觉3D目标检测全球挑战赛第三名;在点云3D目标检测任务上发表ACM MM(ACM Multimedia)国际会议论文2篇、IEEE期刊论文1篇;在点云3D语义分割任务上发表国际顶级会议ECCV论文1篇,获CVPR 2022 Waymo 3D语义分割全球挑战赛的第二名;在驾驶场景图像目标检索任务上获ECCV Commands for Autonomous Vehicles国际竞赛的第一名和第二名,ECCV workshop论文2篇。
1.3自动驾驶介绍
自动驾驶旨在实现代替人类驾驶员操控机动车,是一种新一代信息技术。它使用先进的车载传感器系统对驾驶场景进行环境感知,融合深度学习(Deep Learning)、计算机视觉(Computer Vision)等不断发展的计算机技术,主要包括驾驶场景感知、智能决策规划、自主车身控制等三大流程。这三大流程中,驾驶场景感知是自动驾驶技术要解决的首要任务,包含对场景内容的物体包围框级别的障碍物3D目标检测(3D Object Detection)和细粒度级别的类别3D语义分割(3D Semantic Segmentation)等基础任务。检测结果可用于障碍物避让规划、障碍物轨迹跟踪预测等,分割结果可用于场景元素识别、道路可行使区域识别等,都将直接影响下游的智能决策规划的判断和自主车身控制的操作。因此,准确可靠的驾驶场景感知是实现自动驾驶的研究基础和技术关键。
2.成果1:单目相机3D目标检测工作
Yu Hong, Hang Dai, and Yong Ding, Cross-Modality Knowledge Distillation Network for Monocular 3D Object Detection, ECCV 2022 (Oral Presentation).
基于相机的纯视觉3D目标检测的主要难点之一是从图像的2D信息中准确地推理出3D信息。在模型训练的过程中,借助激光雷达的思想和数据来帮助基于图像的模型是一种主流方案。以伪雷达(Pseudo-LiDAR)方法为例,这类方法通过深度预测将2D图像转变为3D伪点云从而进行3D目标检测,并从真实点云数据中提取深度图用于深度监督。然而,此类方法对于点云数据的利用不够直接、高效,依然存在改进空间。
论文提出了一种创新的跨模态知识蒸馏(Cross-Modality Knowledge Distillation)网络。如图1所示,网络使用一个基于点云的教师模型,在特征层面(Feature Level)和响应层面(Response Level)从点云数据中提取高维语义信息,并通过知识蒸馏(Knowledge Distillation)的技术手段将其转移至基于图像的模型中,从而直接、高效地利用点云所提供的3D信息,大幅提高模型性能。同时,论文提出了一种全新的半监督训练框架以高效利用大规模的无标签数据,在显著降低标注成本的同时进一步提高模型性能。截至提交时,论文所提出方法的性能在KITTI和Waymo等主流自动驾驶数据集上均超越了现存所有的方法,且相对增幅达20% 以上。
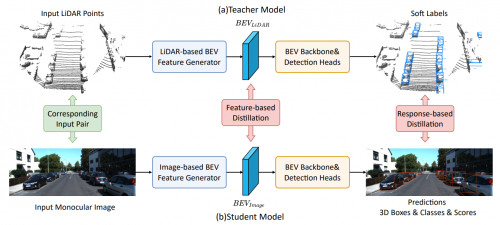
图1 Cross-Modality Knowledge Distillation Network整体框架
3.成果2:激光雷达点云3D语义分割工作
Jiale Li, Hang Dai, and Yong Ding, Self-Distillation for Robust LiDAR Semantic Segmentation in Autonomous Driving, ECCV 2022.
实际场景中常有雨雾天气、不稳定的数据传输等外部因素对激光雷达点云数据造成干扰,影响神经网络模型的预测效果。点云3D语义分割模型的鲁棒性就显得十分关键。论文关注点云3D语义分割模型的鲁棒性分析和提升,最终有效提高了对输入的抗干扰能力,也在SemanticKITTI及nuScenes等3D语义分割大型数据集上取得顶尖性能。
方法框架如图2所示,具体创新性体现如下。第一,针对模型推理的鲁棒性,提出一种基于复合变换的点云分割测试时增强技术,通过复用该复合变换生成多个输入变体送至模型推理,将多个分割结果进行整合,有效消除不同变换视角下的推理不确定性。第二,针对模型训练的鲁棒性,提出一种自我蒸馏(Self-Distillation)训练框架,通过一组结构完全相同的教师-学生模型实现知识蒸馏,提升模型训练效果。为减少对高复杂度的教师模型的额外需求,该论文将第一点中的测试时增强技术应用在教师模型上以保证蒸馏指导的质量。第三,针对点云输入时的体素编码过程,该论文提出一种基于Transformer的体素特征编码器(TransVFE)。它使用多头自注意力机制来对体素内的点进行局部关系建模,以强化局部特征提取过程。
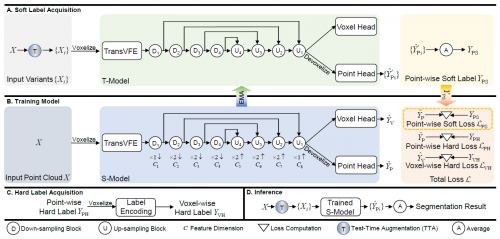
图2 Self-Distillation for Robust LiDAR Semantic Segmentation整体框架



