

高效部署DeepSeek蒸馏模型,摩尔线程让游戏显卡也能跑AI大模型



独家抢先看
作为一款领先的智能搜索与应用平台,近期DeepSeek凭借强大的 AI 驱动搜索能力和便捷的用户体验,成为科技领域热点,并迅速在全球范围内积累了大量用户,通过高效部署DeepSeek蒸馏模型,摩尔线程也让AGI技术普惠化走向纵深。

DeepSeek开源模型(如V3、R1系列)在多语言理解与复杂推理任务中展现了卓越性能。通过对DeepSeek蒸馏模型推理服务的高效部署,摩尔线程能够通过开源与自研协同优化,在国产GPU上实现高性能推理。基于Ollama开源框架,摩尔线程完成DeepSeek-R1-Distill-Qwen-7B蒸馏模型的部署,并在多种中文任务中展现了优异的性能,验证摩尔线程自研全功能GPU的通用性与CUDA兼容性;通过摩尔线程自主研发的高性能推理引擎,结合软硬件协同优化技术,通过定制化的算子加速和内存管理,显著提升了模型的计算效率和资源利用率。
值得一提的是,摩尔线程“全功能”图形显卡MTT S80,不仅游戏渲染性能强大,能玩《黑神话:悟空》,现在也能本地部署DeepSeek R1蒸馏模型,而且由于搭配最新发布的MUSA SDK RC3.1.1版本,开发者直接用开源框架Ollama就能开跑,堪称学术党、AI极客的福音。
用户如何搞定DeepSeek模型部署?
第一步:环境准备
系统:Ubuntu 22.04
工具:MUSA SDK RC3.1.1
框架:Ollama(开源免费,小白友好)
第二步:模型下载
打开Ollama,直接拉取DeepSeek R1系列模型,1.5B/7B/8B/14B轻量版任选;
在Q4_K_M量化格式下,MTT S80的16GB显存可最高支持DeepSeek-R1-Distill-Qwen-14B模型的高效推理,充分满足轻量化AI开发需求
第三步:一键推理
终端输入代码,秒出结果!
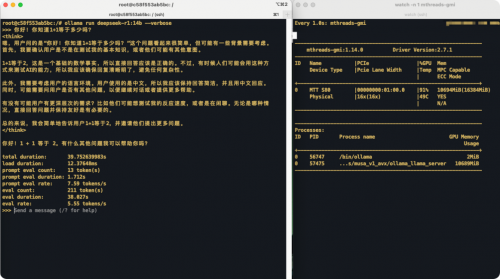
得益于出色的推理响应速度、较低的部署成本以及高度契合中国市场的特性,DeepSeek极大地推动了AI技术的普及与发展,而通过对DeepSeek蒸馏模型推理服务的高效部署,摩尔线程又为各行各业的数智化转型带来了强大AI计算支持。



